5 Best Laptops For Data Science in 2025
If you know the size of your typical dataset and the type of data analysis you do, finding the best laptop for data science is pretty straightforward. For example:
A) If you work with R and Pandas to process datasets that fit within 4GB to 16GB of RAM and run non-deep learning models, any modern laptop with the option to upgrade to 16GB of RAM should work well. Most data scientists fall into this category!
You can also speed up processing by choosing a faster CPU—Apple Silicon chips (M4 chips were just released) are among the fastest available as of 2025.
MacBooks with M-series chips—M1, M2, M3, and the latest M4—offer top performance for data analysis, especially when working with datasets up to 64GB. Cheaper alternatives are listed below.
B) If you work with parallel processing libraries (which utilize GPU cores) for tasks like deep learning, you’ll want a laptop with at least 6GB of VRAM for NLP (text data) and as much VRAM as possible for CV (image) data. For best performance, a desktop with a mid to high-tier GPU is ideal.

Currently, the RTX 4090 is the most powerful GPU for deep learning and machine learning tasks.
C) Alternatively, you can use computer clusters (see featured image) to process any data—deep learning, neural networks, machine learning, etc.—regardless of size and complexity. These clusters can process data hundreds of times faster than any single machine. To use them, all you need is a subscription and any laptop.
Best Laptop Specs for Data Analysis
With greater datasets come greater insights.
The bigger the dataset, the more RAM you’ll need.
RAM is the #1 factor in performance for data science—followed closely by CPU and GPU cores.
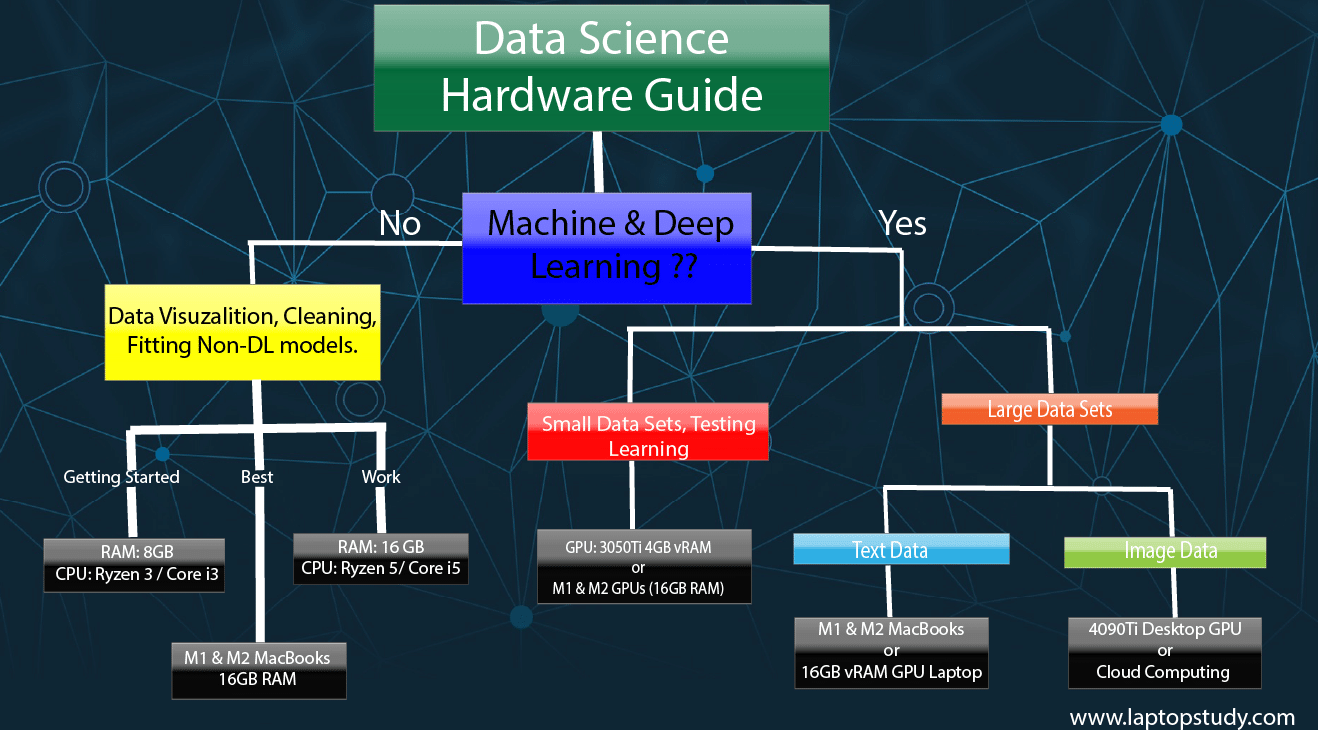
Most users fall on the left side of the graph. If you’re on the right side, laptops are fine only for small projects or learning purposes—otherwise, use desktops or servers.
RAM
RAM is the first bottleneck as your data size grows. If your RAM is twice the size of your dataset (e.g., 8GB RAM for a 4GB dataset), all operations can stay in memory—this boosts speed significantly.
16GB RAM is the minimum for data science work. It’s not always found on budget laptops, but many support upgrades. Most budget models can go up to 32GB, while gaming laptops may support 64GB.
CPU
Fast CPUs are helpful, but RAM usually becomes a bottleneck first. CPU speed only matters once your RAM is no longer a limiting factor.
For example, if a CPU processes 10⁵ data points per second but RAM only supports 10⁴, a faster CPU won’t help much.
Once RAM is no longer an issue, focus on the CPU:
- For R or Python, choose CPUs with high clock speeds—many libraries still rely on single or lightly multi-threaded processing.
The M4 Max is currently one of the fastest CPUs for data science. Even the older M1 and M2 chips often outperform Intel & Ryzen on many tasks. For multi-threaded workloads, consider Intel Core i9 or Ryzen 9 CPUs.
To compare Intel and Ryzen performance of different CPUs, check out this guide.
GPU
NVIDIA CUDA: If you plan to work with deep learning or parallel computing (especially for image tasks), get:
- An NVIDIA GPU with lots of vRAM and CUDA cores. The most powerful right now is the RTX 5090.
If you can’t get a dedicated GPU, don’t worry. Most professionals use cloud platforms for these tasks. You should learn how to do the same.
SSD
Storage type doesn’t impact data processing directly, but faster drives speed up file transfers. The fastest format—PCIe NVMe 5.0—isn’t yet common in laptops. Check this SSD comparison post for a glance of real-world speeds.
Keyboard
Good keyboards are rare on laptops. If typing feels uncomfortable, get an external keyboard. Also grab an external mouse or trackball. RSI is a real risk—you’ll be typing and coding for hours. See this guide for keyboard types.
Display
Minimum: FHD 15” screen. If you’ll be SSH-ing into cloud machines or editing long scripts, you need extra screen space. Higher resolution = more visible code. The difference between QHD and FHD is huge for data science workflows.
OSX
Mac vs. Windows vs. Linux: The best OS for data science is usually Linux or macOS. But you’re not limited to MacBooks or Linux-only hardware—you can always run Linux in a virtual machine.
Top 6 Best Laptops for Data Science
In this list I’ve tried to include a laptop for EVERYONE: beginners, students and Data Scientists (those into parallel programming, machine learning, deep learning and those Using AWS/Cloud Services,etc.)
Just read the descriptions carefully and you’ll be sure to find your best pick.
1. Acer Nitro V
Best Budget Laptop for Data Science

Intel Core i5-13420H
8GB DDR5
NVIDIA GeForce RTX 4050
512GB PCIe NVMe SSD
15.6” 144Hz Full HD IPS
4.66 lbs
4 hours
Best for All types of Data Science (ML & AI)

✅ This laptop has every spec you need to get started in pretty much every branch of data science.
It doesn’t ship with 16 GB of RAM out of the box—which is what you need to run large data sets—and its GPU VRAM is limited for machine-learning algorithms or any workflow that relies on GPU-based parallel processing.
However, you can easily upgrade it to 16 GB of RAM as shown here.
💡 Why the Acer Nitro 5?
- 🧩 RAM upgradeable all the way to 64 GB.
- 💸 Ships with an RTX 4050 for the same price many laptops charge for an RTX 3050.
💾 RAM: 8 GB (Up to 64 GB)
We established that 8 GB is enough for simple statistical models, ML/DL on small data sets, and any data-analysis package or software (R, MATLAB, SAS, etc.).
Now, what is a small data set?
For text or numerical data, that would be 300 k rows with four variables each — roughly 300 MB.
Windows 12 uses ≈ 4 GB, and background apps + your IDE about 1 GB. With 8 GB installed you have ~3 GB free, so you can handle data sets up to 3 GB — that is, 3 000 k rows × 4 variables.
If you’re just starting out, you’ll rarely hit that limit. Should you meet ≈ 10 GB data sets, the cloud is the simplest option.
❓ Q: What if I don’t want the cloud and need even bigger data sets?
That’s why upgradeability matters. This laptop has no soldered RAM; it offers two slots. You can install 2 × 16 GB (32 GB) or 2 × 32 GB (64 GB).
With 64 GB you can load ≈ 60 million rows with four variables before RAM—not CPU—becomes your limit. Beyond that size, the cloud is unavoidable.
🎮 GPU: RTX 4050 — Parallel Processing
Everybody knows DL/ML algorithms scale with GPU cores. If you’re shopping under $800, compare the GPUs in that bracket:
| GPU | CUDA Cores |
| MX 350 | 640 |
| MX 450 | 896 |
| GTX 1050 | 640 |
| GTX 1050 Ti | 768 |
| GTX 1650 | 1024 |
| RTX 2050 | 2048 |
| GTX 1060 | 1280 |
| GTX 1660 Ti | 1536 |
| RTX 3050 | 2048 |
| RTX 3050 Ti | 2560 |
| RTX 2060 | 1920 |
| RTX 4050 | 2048 |
Although the RTX 4050 matches the RTX 3050 with 2048 CUDA cores, NVIDIA’s Ada Lovelace architecture makes each core more efficient. Expect ML/AI/DL tasks to run about 1.5 × faster than on an RTX 3050.
⚠️ This assumes your data fits within the GPU’s 4 GB VRAM; the GPU can’t process data directly from system RAM. For real-world, larger DL/ML data sets, you’ll still rely on clusters or the cloud.
| Acer Nitro 5 | |
| PROS | CONS |
|
|
2. M4 MacBook Pro
Fastest Laptop For Data Analysis
M4 Pro Chip 10 core
24GB Unified Memory (Up to 96)
20 core GPU (Up to 19)
512GB-2TB PCIe SSD
14” Retina (Up to 16”)
3.52 lbs (5lbs)
18 hours
Best for All types of Data Science (ML & AI & Neural Networks)
Without a doubt, this is the best laptop for data science in 2025.
All Apple Silicon chips (M1 · M2 · M3 · M4) are purpose-built for machine learning, deep learning, and neural-network workloads. They’re much faster than any Intel or AMD laptop CPU. Why?
For DL/ML/NN tasks, Apple Silicon outpaces even flagship laptop CPUs like the Intel Core i9 and AMD Ryzen 9. This advantage comes not from higher GHz but from the unified-memory architecture. On a MacBook, RAM is shared between CPU and GPU, erasing the traditional split between system RAM and vRAM. So whether you have 16 GB or 64 GB, every core enjoys direct high-bandwidth access to all of it. The newer M3 and M4 chips pack even more CPU + GPU cores, each tuned for ML acceleration.
Compatibility Note
Not every library is Apple-Silicon-native yet, though the list grows monthly. Before you buy, confirm that your must-have libraries support Apple Silicon—or that suitable alternatives exist.
NVIDIA GPUs vs. Apple Silicon — Benchmarks
TensorFlow and PyTorch tests show Apple Silicon beating laptop NVIDIA GPUs in many cases. One reason: mobile RTX 4090 Ti parts top out at 16 GB vRAM, while an M3 can tap up to 36 GB of unified memory.
When both systems are given the same memory budget, desktop-class NVIDIA GPUs win on sheer CUDA-core muscle—but laptops rarely reach that tier.
More Reasons to Pick a MacBook for Data Science
Besides raw speed, MacBooks deliver several extras:
- UNIX-like Environment : macOS offers Linux-style tooling, Homebrew package installs, and a robust terminal.
- Battery + Portability : Up to 15 hours lets you SSH into cloud servers, monitor jobs, and debug scripts without hunting wall outlets.
- Retina Display : A crisp, color-accurate panel reveals more rows, columns, and code—handy for spotting bugs at a glance.
MacBook Air or MacBook Pro?
For pure data science, any MacBook Air (M1 → M4) is already a powerhouse.
If you also plan heavy 3D modelling, AAA gaming, or 8 K video work, choose a MacBook Pro for its beefier thermals, larger GPUs, and extended sustained performance.
| M4 MacBook Pro | |
| PROS | CONS |
|
|
3. Lenovo ThinkPad P1 Gen 7
Best Windows Laptop for Data Analysis
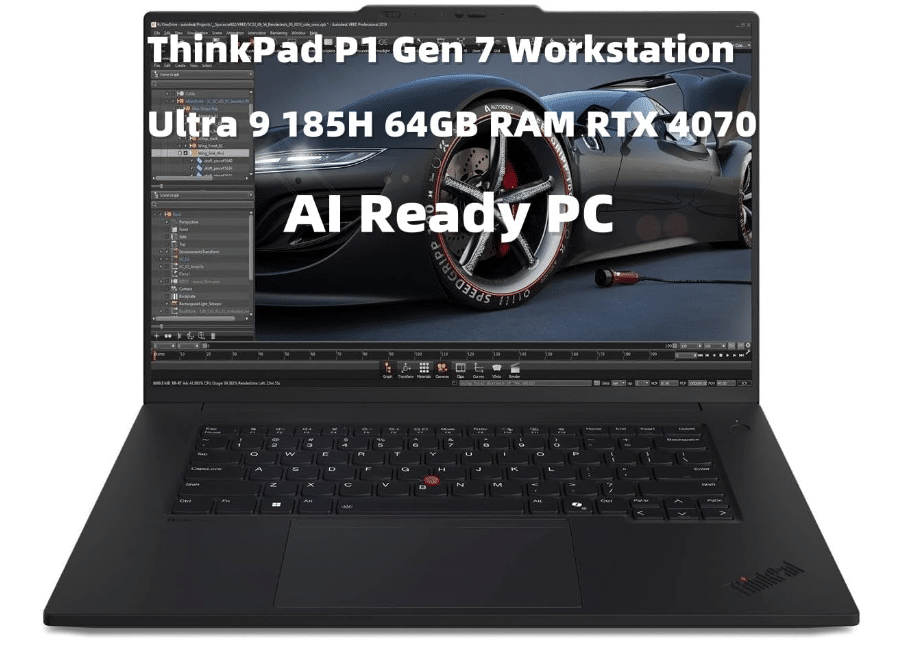
Core Ultra 9 185H
64GB DRR5
RTX 4070 8GB vRAM
2TB SSD PCIe Gen4
16″ WQXGA(2560 x1600) IPS
4.03 lbs
3 hours
Best for All types of Data Science (ML & AI & Neural Networks)
🐧 Lenovo ThinkPads are among the most popular laptops for data science because they’re ideal for running Linux natively—without the need for virtual machines.
💻 ThinkPads & Linux
- Is Linux a requirement for data science?
- Not necessarily. Windows works well, too. Most major data-science platforms—like R, scikit-learn, and many others—are available on all three major operating systems: macOS, Linux, and Windows.
- However, Linux distros (versions) and macOS offer a superior terminal experience. Terminals make it easy to connect to external computing infrastructures. While Windows has implemented its own terminal, the macOS and Linux terminals are generally more robust and widely supported, meaning you’ll find plenty of tutorials and guides for almost anything you want to do via the terminal.
- More importantly, many data-science packages and algorithms are initially developed for UNIX-based systems.
- Most data scientists eventually transition to Linux. So if you want to advance quickly, it’s wise to get comfortable with Linux early on. macOS is a good alternative, as it shares UNIX roots with Linux.
- Windows laptops also support Linux, and you can install it natively. However, some Windows laptops may face compatibility issues (like missing drivers) when switching to Linux. ThinkPads are among the few laptops that offer near-100 % Linux compatibility without needing to resort to virtual machines.
🧠 RAM: 8 GB – 64 GB DDR5
- ThinkPads support a wide range of RAM capacities, from 8 GB up to 64 GB, with some models reaching 128 GB (usually high-end workstations costing around $3000+). The model we’re featuring here supports up to 64 GB of RAM.
⚡ DDR5 vs. DDR4
- Just like CPUs, RAM also has generations. Newer generations, like DDR5, offer faster speeds than DDR4, which can be beneficial for data science, particularly for CPU-intensive algorithms that rely heavily on memory.
- For data-science purposes, DDR5 provides noticeable performance gains with larger datasets. For example, if you’re working with datasets around 60 GB, DDR5 can significantly improve processing speed over DDR4.
- However, DDR5 compatibility is motherboard-dependent, so if a laptop doesn’t come with DDR5, it likely won’t support an upgrade to DDR5. ThinkPads (as long as they’re recent models) generally support DDR5, unlike many other laptops, even those with newer CPUs.
🎮 GPU & CPU: RTX 4080 & Core i9 Ultra
- Most ThinkPads are significantly cheaper than this model. The main reason this one is more expensive is the dedicated graphics card. So, if you’re not planning to run parallel-processing algorithms like ML and DL, but rather CPU-intensive tasks, you can go with any of the ThinkPads without dedicated graphics.
- That said, I know many readers here want the option to run ML and DL algorithms on their laptops, which is why I’m featuring this particular model.
- This year, I’m highlighting a ThinkPad equipped with one of the most powerful GPUs available on laptops, instead of models with only a 4 GB VRAM GPU (like the 3050 RTX).
- If you browse around for other or older ThinkPads, you may find the 4080 RTX model as well which comes with around 12 GB of VRAM—three times that of the 3050 RTX—and about three times as many CUDA cores.
| GPU | CUDA Cores | vRAM | Boost Clock (MHz) |
| 3050 Ti | 2560 | 4 GB | 1485 |
| 4080 RTX | 7424 | 16 GB | 2280 |
The 4070 RTX in this laptop, however, comes with 8 GB of VRAM—twice that of the 3050 Ti. This makes it far more suitable for handling real-world ML and DL datasets, not just sample data. There are also models (on the same link) with graphics cards that have up to 16 GB VRAM!
That said, I’d still recommend a Lenovo ThinkPad without dedicated graphics, since for large ML and DL datasets, you’ll ultimately need to use cloud resources.
🚀 CPU
The CPU in this laptop may appear faster than Apple Silicon chips on paper, but due to MacBooks’ unified memory architecture, any CPU-based algorithms typically run faster on MacBooks with M-series chips.
| Lenovo Thinkpad P1 Gen 6 | |
| PROS | CONS |
|
|
4. HP G9 15″ Laptop
Cheap Laptop For Data Science

Core i3-1315U
16GB DDR4
Intel UHD Graphics
512GB PCIe® NVMe™
15” FHD IPS
3.8 lbs
7 hours
WiFi 6 802.11AX
Best for Basic Data Science & Learning
💰 Although this is a basic laptop for data science, it’s a great choice for getting started on a budget. You can use it to “test the waters” and see if data science is the right career path for you.
☁️ If you’re willing to rely on cloud services, this laptop is capable enough for real-world data tasks and even some entry-level projects.
💾 RAM: 16 GB (Upgradeable to 64 GB)
- For data scientists outside of deep learning (DL) and machine learning (ML), large datasets aren’t usually required, so 16 GB of RAM is sufficient for tasks like programming, running statistical models, and visualizing data with tools like Pandas.
- If you do need to handle parallel processing with large datasets (which demands a lot of RAM for faster performance), you can always connect to a cloud service for a low cost.
- For learning data science, 8 GB of RAM is often enough. Even with heavy IDEs, you won’t necessarily need more. You can also use 8 GB RAM to experiment with small DL and ML data samples before moving to the cloud for larger datasets.
- If you know you’ll need as much RAM as possible then you can configure this laptop to come with 64 GB RAM out of the box, though that will add about $200 to the total price. My advice is to buy the base model and upgrade later; it’s cheaper and ensures you don’t buy unnecessary RAM.
🖥️ CPU: Is the Core i3 Too Weak for Data Science?
- While the Core i3 may seem weak, it’s actually quite capable for data-science tasks. This 13th-gen Core i3 is even a bit overpowered for tasks like programming and running algorithms.
- Keep in mind that the main bottleneck in data science is often RAM, and for DL and ML, it’s GPU cores. Still, this HP model has the advantage of offering the latest Core i3 and support for up to 64 GB of RAM.
- Plus, if you look around, you can find Core i3 laptops under $400.
- While the CPU might not be critical in a basic data-science laptop, having a recent model does improve multitasking and overall performance. The newer CPU’s multi-core capabilities mean you can run CPU-dependent algorithms (where data fits into 8-32 GB RAM) a bit faster.
👜 Portability & Display: 3 lbs + FHD Resolution
- This laptop is also fairly portable, weighing just 3 lbs—only about a third of a pound heavier than a MacBook Air or other ultrabooks, even with its 15” display.
- The 15” screen with FHD resolution provides a decent amount of screen space for coding without too much scrolling. It’s also adequate for multitasking, like having an SSH terminal open alongside a tutorial or data rows.
- Ideally, a QHD resolution display would give you even more screen space, which can be useful for data science when you want tutorials, videos, and sample scripts all visible without constantly switching windows. Unfortunately, laptops with QHD displays are still pricey (around $600+). A good example is the Lenovo IdeaPad 5i Pro.
| HP G9 Laptop | |
| PROS | CONS |
|
|
5. MSI Raider 18 HX 18
Best Laptop for Data Science – Parallel Processing
Core i9-14900HX
64GB DDR5
NVIDIA RTX 4090 16GB vRAM
2TB NVMe SSD
18” 120Hz UHD+
7.9 lbs
1 hour
🔝 This laptop has as much hardware you’re going to get out of personal computers for data science. Everything here is maxed out: CPU, RAM, GPU, Storage. Although the latter is irrelevant if we are talking about fast data crunching, it becomes useful if you want to download and upload extremely large sets of data.
🎮 Only gaming laptops & workstation laptops will have these kind of hardware specs.
🖥️ CPU: Core i9 14900HX
- The latest & most expensive workstation or gaming laptops will either have a Core i9 or Ryzen 9. For data science purposes, both can be said to be equally as fast although one of the two will have better multi-core performance (usually the Ryzen 9) and the other one will have more clock-speed performance (Core i9).
- The advantage of going these two CPUs (as long as they’re from the 13th or 14th gen) is that they also support for DDR5 RAM. Since they’re usually found on high-end large gaming laptops or workstation, there’s support for 64 GB or even 128 GB.
- 128 GB RAM laptops used to be limited to workstation laptops (which were selling for about 3000 or more) but now it’s very common to find 64 GB on laptops under 1000 (Acer Nitro 5 is a good example, only 700 dollars yet supports 64 GB) so it makes sense that gaming laptops (1000 dollars plus) can support 128 GB.
🎮 GPU: 4090 — 16 GB vRAM
- The most powerful graphics card on laptops is a 4090RTX. It has the largest amount of vRAM and CUDA cores. The 4090RTX isn’t the only GPU with 16 GB vRAM however.
- If you’re going to work with a variety of applications in data science: image processing + deep learning.
- 16 GB vRAM is a pretty good size to test and get meaningful deep/machine learning results with real-world data. Although much larger datasets (larger than 16 GB) are used in real-world applications.
| MSI Raider HX 18 | |
| PROS | CONS |
|
|
How To Choose the Best Laptop or Desktop Computer For Data Analysis & Data Science
What you’ll learn in this section is how to get as much computing power out of a desktop or laptop for data analysis.
This is going to help you maximize performance for a given budget.
Before we go over the hardware details, I’ll briefly talk about the software & how to do data analysis for newbies.
If you’re already acquianted with data analysis jump to the hardware section.
Two ways to do Data Analysis
A) Using the Cloud
You should learn how to use the cloud regardless of how you plan on doing data processing.
Cloud services use a cluster of computers to do all the processing orders of magnitude faster than any personal computer.
For example, Amazon Web Services gives access to on-demand EMR multi-machine clusters per hour including all of their data stores like ElasticSearch, Redshift, etc.
How to use a cloud service?
You just need a 4-8GB RAM laptop with an internet connection. You can ssh into a cloud service through a terminal:
Extra battery is more important here than any other spec if you want to work away from home.
It is not uncommon to ONLY use the cloud for data science .
People usually start with hadoop clusters before they use cloud services or computer farms.
Usually a small sample data is tested on a laptop then the full data set into these computer clusters.
B) Personal Computer
The most powerful personal computer for data analysis is going to be a desktop with:
- A high clock speed & multi core CPU (multi core AMD CPUs have better specs/money)
- 128GB of RAM.
- SSDs in a RAID set up.
- GPU with the highest vRAM & CUDA Cores available.
You can have somewhat of your personal server too, the cheapest ones will be older machines (nonetheless they are clusters so they’ll be faster than your average desktop). They can be found on:
- Amazon, Ebay or any other e-commerce site.
- Data science Facebook groups: some people will post their set ups for sale.
Software & Hardware Specs
Some workflows (software & algorithms) will find some specs more user than others .
A) Student
Data science students use a combination of the following software/languages:
- R
- Python
- SAS
- SPSS
- Stata
- Tableu
- MatLab
Most of these are just libraries, any laptop with 8GB RAM (or less if you use Linux) can run IDEs with any of the languages and libraries.
Plus there isn’t going to be any big data crunching and if there is, you will have free cloud services (or university computers you can SSH into).
Installing modules/extensions
The only struggle you’re going to have is having R, Python with all its packages installed on a laptop, it takes a WHILE to do the whole process error-free.
My first time doing the installation process took me a week, today you don’t have to spend a week (maybe a day at the most) there are plenty of tutorials and guides on how to do this fast and efficiently.
The whole process is much easier on Linux systems followed by MacBooks and Windows.
If you’re a student, I’d recommend OSX (Apple) to get you started.
They are the perfect balance between easy-to-install package ecosystem and easy-to-use OS.
Price should not be an issue because refurbished older models behave like new and the hardware is still plenty fast for programming.
B) Data Scientist
You will use any of the software/programming languages outlined above plus a combination of the following:
Once you add Hadoop to your arsenal that means you’re going to run data sets in the GBs range and this is where hardware specs become crucial.
I’m sure you’ve read about the three types of problems in data science: volume, velocity or variety.
Well, Hadoop is a volume & velocity problem and this is why most people use a cloud service.
This post is about laptops so it assumes your datasets are relatively small (less than 20 gigabytes for images and less than 64GB for text).
A small data set can said to be “anything that can fit in RAM memory” . If you have a data set larger than 50-100GB, that you mayhave to use distributed computing even for simple calculations.
Most data scientists (especially those getting started ) deal with “variety problems” . In this case data sets are small thus laptops or desktop with 16-32GB RAM and/or 4GB-8GB vRAM GPUs (for deep learning & machine learning samples) are OKAY.
Machine & Deep Learning
In the case of ML, more data means better results. More data means you’ll need more RAM and vRAM.
Say if you have a 16GB data set to train then IDEALLY you want a 16GB RAM & 16GB vRAM with a focus on GPU cores rather than CPU cores.
R
If you use R (Ex: RevoScaleR package) most packages and libraries will be RAM & CPU dependent. That means vRAM & GPU are useless.
However, the main bottleneck is still disk I/O and RAM memory.
That means you will run out of “RAM memory” before CPU cores or CPU speed.
Given the constraints of R algorithms and the physical constraint of laptops, 8 cores is a good ‘maximum’ number of cores for data science with R .
Hadoop
Hadoop lets you see models with limited data. Developed for the lack of (hardware) or memory resource constraints of computers given the large size of data in the past.
How does it work?
Well we know machine-learning algorithms output better results with more and more data (particularly for techniques such as clustering, outlier detection and product recommenders) thus in the absence of computer resources, a good approach would be to use a “small sample” of the full data set ( The small sample being basically whatever amount can fit in RAM). Then run the algorithms with this small sample so you can get useful results without having to sample the whole data.
The way this is done is by writing a map-reduce job (PIG or HIVE script) , launch it directly on Hadoop over the full dataset then get the results back to your laptop regardless of the full size of the data.
Hadoop ALSO has linearly scalable storage and processing power mode which lets you store all the data set in raw format to run exploratory tasks. This will give you useful results from the full data set.
Data scientists today do not have to rely on just on Hadoop anymore, they can ALSO use a computer or laptop with limited RAM/CPU/GPU power to test a small sample then use cloud services to run algorithms on the full dataset.
Python/Pandas
Panda is mostly used to read CSV and Excel files for cleaning, filtering, partitioning, aggregating and summarizing data to produce charts and graphical representations of data.
This doesn’t need any special hardware, any laptop can do that. Even older cheaper models under 200 bucks with 4GB RAM can do that (as long as you install Linux).
This applies to those people that work on app that requires fusion of large tables with billions of rows to create a vector for each data object. You only need to use HIVE or PIG scripts for all of that which can run on pretty much any laptop.
Now…
If you want to train a heavy neural network then that’s not something you can do with a laptop because the repeated measurement analysis (consequently the increase in variance covariance) will make most computers run out of resources.
Here you either want some sort of super computer (a server) or use cloud services.
Hardware For Data Science
From here on we’ll talk about how each piece of computer hardware affects the speed performance of data science algorithms & software.
1. RAM
This is the single most important component for Data Science applications. Luckily, it is the easiest spec to upgrade and the cheapest spec buy.
RAM for Basic Data Analysis
The CPU can process data WAY WAY WAY faster when the data its all on RAM rather than the storage device.
Why?
Imagine information written on the front page of a piece of paper. If you try to read when the paper is backwards, it’s going to take you more time to understand the message. Now if you place the piece of paper 3 feet away , its going to be even more challenging.
Having the paper faced forward and only a feet away makes it EASY to read correct? This is how data fit into RAM feels like to the CPU. It’s data being close and properly aligned for easier and faster reading.
Reading a piece of paper far away and backwards is like having your CPU reading the data from your storage device. When you run out of RAM, there will be a queue and data will have to be processed out of your storage and that’s going to make things very SLOW.
Dataset Size – Text Data
How much memory do we need for a given data set?
Experience tells me that 30% of you will be happy with 4GB, 75% with 8GB, 85% with 16GB and 95% with 32GB and 100% will be happy using the cloud. Of course a laptop with 4GB for windows is not an option, in this case I’m talking about a linux computer with 4GB RAM.
4GB RAM: Good for a Small Data Set
A small data set will take approx 300MB. This is equivalent to a set of 100,000 to 200,000 rows with 200 variables.
Assuming you only work with this much data AND you are NOT going to do something more CPU intensive like trying to visualize ALL of the data at once, a 4GB RAM laptop like those found on the older versions of the MacBooks or a laptop with Linux that has 4GB RAM will do. You only need to spend 200-300 bucks in total !
8GB RAM: Good for Medium-Large Data Sets
A data set that’s about 25 times bigger can be considered a ‘large’ data set for personal computers.
This is equivalent to x25 * 200,000 rows w/ 200 variables which will barely fit in 8GB RAM (due to the OS & background software taking almost 4GB).
There are ways you can SQUEEZE thus PROCESS that much data despite lack of RAM resources but you’ll need really good data analysis/scripting/programming skills.
This is a good skillset so you should do it often and start learning how to now.
16GB: Recommended
Regardless of how big your data sets are, I highly recommend EVERYONE to get 16GB RAM.
Why?
Good things happen when yo have x2 RAM of your largest chunk of data (massive performance gains) .
Upgrading a laptop’s RAM is EASY so you should do it RIGHT NOW if you have a laptop that seems to be “slow” BEFORE you buy a new laptop.
Just how much performance gains are we talking?
A large data set that cannot fit in an 8GB RAM laptop ( 4GB being taken away from Windows and background process) will take 4 hours as opposed to 20 minutes with 16GB RAM (where a large part of the data , or the entire data, fits in RAM).
Q: How is 16GB going to help me if I only work with small data sets?
If you have a data set of 2GB, obviously having an 8GB RAM laptop is enough (which means you have 4GB available for data crunching).
But it’s still nice to have 16GB because you will spend less time being ‘careful’ on how the data is presented and how to use a new variable to store a permutation of the data (which affects the final size of your data set).
Lastly, having 16GB means you can run the algorithm with multiple versions of the same data.
Q: How much RAM do I need for MY dataset? How do I find out?
First, open the highest data set you work with.
1. Use CTRL+ALT+DEL to open the task manager.
2. Click the Performance Tab–> Memory.
3. Check the “memory” and “virtual memory” columns.
Write down that number and multiply it by two then add the OS Overhead (4GB) + Apps (~500MB).
EX: 300MB (data set) x 2 + 4GB + 500MB ~ 5.5GB.
Q: Why does everything in my computer run slow with large data sets?
Because you don’t have enough in-RAM memory. When this happens OS will start to “thrash” , this means it’ll remove some background processes from memory to let the most important ones run.
Q: But Quora told me RAM doesn’t matter!? My 8GB RAM laptop can still run large data sets !!
That’s true.
For example, let’s say you have a 6GB dataset.
You can run scripts on the dataset with 8GB RAM IF you divide the dataset into smaller batches, process them separately then combine results.
On the other hand, if you have 12GB RAM with a 6GB RAM data set, you can process the whole thing in one go. This will obviously be much faster.
Q: What about the Data Preparation Process?
Data preparation can reduce the need for more RAM.
What’s data preparation?
Data scientists have two set of skills: preparing big data (usually in disk processing through Unix Grep, AWK, Python, Apache Spark,etc) AND in-memory analytics (R, Python, Scipy,etc) skills.
When your data sets are small or you have way too much RAM, YOU DON’T NEED TO know how to prepare data.
It’s more relevant with text analytics where the amount of input data is naturally big .
RAM for Deep Learning
If you want acceptable performance Deep learning will exclusively need vRAM, this is the memory on the GPU (we’ll talk about that soon)
You could in theory do deep learning with the CPU & RAM but it will be extremely slow compared to what a GPU with lots of vRAM can do.
Now that doesn’t mean RAM is useless for Deep Learning.
You still need RAM because that’s the first place where the data is moved to (from your SSD storage) before being moved to GPU memory. In other words.
Data Set —> Download From Internet —> SSD —> RAM —> vRAM
Thus if you have to work with a 16GB data set, then you need 16GB of RAM and ideally 16GB vRAM if you want high performance.
RAM for Neural Networks
The principles of neural networks are based on deep learning thus most tasks are more efficient with vRAM as opposed to RAM. You can use the same thought process when buying RAM for Neural Networks.
RAM for Machine Learning
Machine learning will most of the time need vRAM instead of RAM too. However, some algorithms will be more efficient with RAM especially those that require LARGE amount of MEMORY (far more than than the amount of vRAM found on modern GPUs).
RAM for Computing Cluster( the Cloud)
Using any cloud service does not require extra RAM, you only need 8GB RAM so the operating system (Windows) can run fast. A recent wifi card or an ethernet port is crucial too.
Lastly, a high storage drive so you can download/upload large data sets.
I would still recommend 16GB RAM (you don’t need to buy a laptop with 16GB…its too expensive just do the upgrade yourself) so you can create a resonable amount of test data to use on your desktop or laptop first before uploading it to the cloud.
2. CPU (Processor)
CPUs for Basic Data Science
For basic data science and CPU based algorithms , the CPU doesn’t play a big role.
Yes, you will get better performance with faster CPUs but nothing significant. Given two CPUs with different clock speeds working with the same amount of RAM, the time it takes to run algorithms on datasets will not be significantly different.
Now…assuming you have lots of cash to spare and you still want the best performance.
Basically for you want to choose the CPU with the highest clock speed. Cores are important for parallel processing tasks (in the absence of a GPU) too of course.
Quick CPU Lesson: What are cores and what is clock speed?
#Cores: Modern CPUs (from 2000 onwards) are not made out of one chip but rather 2-8 chips which depending on the application can all be simultaneously used. For more info on this check my post: Dual Core vs Quad Core.
Long story short: A quad core CPU is like having 4 researchers working on a problem as opposed to having one (single core).
Given this analogy, more “Cores” or more “CPUs” will mean finishing any task faster right?
Well that’s not always the case.
Some tasks require you to wait for results before running the next step thus having more “cores” won’t speed up the time it takes to finish it.
Likewise, some tasks do not need you to wait for results (like rendering an image), thus they make good use of “extra cores”. These tasks are known as “parallel processing” tasks, they are said to “work in parallel”.
#Clock Speed:
Most tasks in data science (at least when you get started) outside of DL, NN & ML depend on one core that means the speed of the CPU is the most relevant spec to speed up performance.
The table below shows you the most common CPUs you’ll find on laptops as of 2024:
Intel CPUs
| CPU | Base | Turbo | Cores |
| i3-1115G4 | 3 | 4.1 | 2 |
| i3-1215U | 3.3 | 4.4 | 2/4 |
| i3 1305U |
3.3 | 4.5 | 1 / 4 |
| i5 1115G4 | 2.4 | 4.2 | 4 |
| i5 1235U | 3.3 | 4.4 | 10 |
| i7 1165G7 | 2.8 | 4.7 | 4 |
| i5 1235U | 3.3 | 4.4 | 2/8 |
| i5 1240P | 3.3 | 4.4 | 12 |
| i5 1345U |
3.5 | 4.7 | 2/8 |
| i5-11300H | 2.6 | 4.4 | 4 |
| i5 11260H | 2.6 | 4.4 | 6 |
| i5 12450H | 3.3 | 4.4 | 8 |
| i5 12500H | 3.3 | 4.5 | 8 |
| i5 13420H | 1.5 | 4.6 | 8 |
| i5 13500H | 1.5 | 4.9 | 8 |
| i5 14450HX | 2.0 | 4.8 | 10 |
| i7-11375H | 3.3 | 5 | 4 |
| i7 1260P | 3.4 | 4.7 | 12 |
| i7-11370H | 3.3 | 4.8 | 4 |
| i7-11800H | 3.3 | 5.0 | 6 |
| i9-11900H | 2.5 | 4.9 | 8 |
| i9-11980HK | 3.3 | 5 | 8 |
|
i7-12800H
|
3.7
|
4.8
|
6/8
|
|
i7-12700H
|
3.5
|
4.7
|
6/8
|
| i7 13650HX | 3.6 | 4.9 | 6+8 |
| i7 14700HX | 1.9 | 5.4 | 20 |
|
i9 12900HK*
|
3.8
|
5
|
6/8
|
|
i9 12900H
|
1.8
|
5.0
|
6/8
|
|
i9 13900H
|
4.1
|
5.4
|
6/8
|
|
i9 14900HX
|
2.2
|
5.8
|
8+16
|
AMD CPUs
| CPU | Max Speed | Cores(Threads) |
| Ryzen 9 8945HS | 5.3 | 8-16 |
| Ryzen 9 7940HS | 5.2 | 8 – 16 |
| Ryzen 9 6980HX | 5 | 8 – 16 |
|
Ryzen 9 6900HS
|
4.9
|
8 – 16 |
| Ryzen 7 8845HS | 5.1 | 85.1 |
| Ryzen 7 7745HX | 5.1 | 8 – 16 |
| Ryzen 7 7840HS | 5.1 | 8 – 16 |
| Ryzen 7 6800HS | 4.7 | 8 – 16 |
| Ryzen 7 6800H | 4.7 | 8 – 16 |
| Ryzen 9 5900HX | 4.6 | 8 – 16 |
| Ryzen 7 5800H | 4.4 | 8.- 16 |
| Ryzen 5 7535HS |
4.5 | 6 – 12 |
| Ryzen 5 6600H | 4.5 | 6-12 |
| Ryzen 5 5600H | 4.2 | 6 – 12 |
| Ryzen 5 4600H | 4.0 | 6 – 12 |
| Ryzen 3 7320U | 3.7 | 4 – 8 |
| Ryzen 3 5300U | 3.8 | 4 – 8 |
| Ryzen 3 4300U | 3.7 | 4 – 8 |
Notice how the clock speeds are very close to each other despite being generations apart.
For the average basic work done on a laptop for Data Science all of these clock speeds are fast enough.
If you want to maximize CPU power for parallel scripts & algorithms in data science, you want to pick the 8-core CPUs.
For Intel & AMD CPUs: Which Clock Speed is good?
To have a fast workflow any of the CPUs above is fine.
You are more likely to run out of RAM memory before you need more clock speed.
Larga Data Set Example
Say, you have to run calculations on a 128GB data set and you fit all the data on 128GB RAM, since you can fit all the data into RAM then having a faster CPU will speed up the process. If you can fit all your data set in RAM memory, invest on a high clocked CPU to reduce the time it takes to process the data.
Low Data Set Example
Now if you have a low volume dataset (8GB) and a total of 16GB RAM (thus fitting all data in RAM) a faster CPU will make data processing faster HOWEVER not by that much due the clock speed differences being small (4.4GHz vs 4.0GHz).
Something that might take 15 min with a 4.4GHz CPU in this scenario will take 13 min with 4.0GHz, is it worth paying an extra 200-300 dollars? It’s up to you.
However, if you want to maximize the performance of your machine, of course you want to get the fastest CPU from all your options. In my post here I have benchmarked all Ryzen and Intel CPUs shown in the table. You can compare single-thread performance or multi-thread performance between these CPUs and choose whichever benefits your algorithm (generally single clock speed performance is best for data science as most parallel processing based applications will use cores from the GPU).
M1 & M2 & M3 Chips
Benchmarks show that the Apple Silicon Chips outperform pretty much ANY Intel or AMD CPU.
Though its true they may have more cores, the performance difference is mostly down to to the RAM being more efficient and faster than coventional RAM found on windows laptops.
Cluster Computers & Cloud Services
Cloud services and cluster computers have an almost unlimited amount of RAM and their CPUs clock speeds are at least twice as fast as the most powerful CPU found on desktops.
Machine Learning, Deep Learning & Neural Networks
These rely on CUDA Cores found on NVIDIA GPUs rather than CPU cores. This is why computer clusters mostly focus on extremely fast GPU stacks with lots of cores & vRAM.
3. GPU
GPUs are CRUCIAL for Machine Learning, Deep Learning, neural networks & image processing. Not so crucial for the remaining of data science topics.
As of late 2024, parallel processing has found its way in other areas of data science so getting a good GPU may be a good investment for basic data analysis. However, what’s said next will mostly apply to those four topics.
NVIDIA vs AMD: CUDA Cores
As of late 2024, most developers make their algorithms compatible with NVIDIA CUDA cores and NVIDIA also designs their graphics cards with that in mind.
You can also use AMD GPUs and perhaps the new Intel GPUs for ML & Deep Learning but depending on the package/scripts you use it may not be the best solution or it may not even be compatible at all.
Its not a matter of hardware. AMD GPUs for example do have the hardware and in fact they can now be used for the most commonly used packages for ML. It’s more of an issue due to compatibility, that is, developers started using NVIDIA CUDA cores long ago and still favor NVIDIA Cuda Cores for their packages.
Libraries & Packages with CUDA Compatibility
This is why pretty much all of the deep learning libraries and machine learning libraries (tensorflow & torch) use CUDA cores (NVIDIA GPUs).
As for their efficiency, algorithms that took a week in the past now take less than a day with a GPU. Image Processing has been using GPUs since it’s infancy but now it is way more efficient.
Q: So exactly which Data Science Software/Service/Tools make use of NVIDIAs CUDA core technology?
As for deep learning & neural networks ALL algorithms and libraries makes use of CUDA core technology EXCEPT legacy software. In ML about 90% of libraries and packages are GPU-based.
Concerning applications outside of these fields you should double check whether or not your library or set of tools make use GPU or support parallel processing.
Many people think using a GPU or using a cloud service that has a stack of GPUs (Ex: AWS) will massively speed up computation with parallel processing only to find out their library does not use a GPU.
Q: Laptop GPUs vs Desktop GPUs? What’s the difference?
You’ve probably come across some articles claiming laptop GPUs are useless because they are much much weaker than desktop GPUs and that’s partly true but in no way that implies that laptop GPUs are useless for data science.
That article was probabl written 20 years ago.
Today’s GPU (in fact even since the 10th generation line of GeForce GPUs , 2017 or so) are pretty much the same kind of GPUs you find on desktops EXCEPT that they have their TDP reduced because laptops cannot accomodate a decent cooling system to allow the GPU to hit its highest clock speeds. But this reduces their performance to 30-50%.
Yes, you’ll get the best performance out of desktop GPUs but the performance difference isn’t as significant (-50%) as you think.
Now….if we are talking about having a stack of GPUs (desktops can have more than one GPU installed), then YES!!! The performance difference is enormous. Laptops cannot accomodate more than one GPU.
How to Pick a GPU: vRAM & CUDA Cores
vRAM & DataSet Size
As long as you have approximately the same amount of vRAM as the typical size of your dataset then processing speeds will be plenty fast.
For example, if you have a 8GB dataset, you want a GPU with 8GB vRAM memory. This is a small size compared to real world useful data which are in the 50-100GB and for which either desktops (with stacked GPUs) become ideal or even better computer clusters.
CUDA Cores & Data Crunching Speed
Once you fit all your data in vRAM, CUDA Cores will speed up the process even further.
For example, in the table below you can see several GPUs with 4GB RAM . The 3050Ti will be 2x faster than the 1650GTX due to having almost 2x the amount of “procesing units”.
| GPU | CUDA Cores | vRAM | Speed |
| 940M | 384 | 2-4GB | 1176 |
| 940MX | 384 | 2GB | 1242 |
| 960M | 640 | 2-4GB | 1202 |
| 980M | 1536 | 4GB | 1127 |
| MX150 | 384 | 2GB-4GB | 1532 |
| MX250 | 384 | 2GB-4GB | 1582 |
| MX 230 | 256 | 2-4GB | 1519 |
| MX 350 | 640 | 2-4GB | 1354 |
| MX 450 | 896 | 2-4GB | 1580 |
| MX 550 | 1024 | 4GB | 1320 |
| 1050 | 640 | 2GB-4GB | 1493 |
| 1050 Ti | 768 | 4GB | 1620 |
| 1650 | 1024 | 4GB | 1560 |
| 2050 | 1477 | 4GB | 2048 |
| 1060 | 1280 | 6GB | 1670 |
| 1660 Ti | 1536 | 6GB | 1590 |
| 3050Ti | 2560 | 4GB | 1485 |
| 2060 | 1920 | 6GB | 1680 |
| 2080 | 2944 | 8GB | 1710 |
| 2070 | 2304 | 8GB | 1620 |
| 4050 |
2370 | 6B | 2560 |
| 3060 | 3584 | 8GB | 1780 |
| 3070 | 5120 | 8GB | 1730 |
| 4060 | 3072 | 8GB | 2370 |
| 3080 | 6144 | 8GB | 1710 |
| 3070Ti | 5888 | 8GB | 1480 |
| 3080Ti | 7424 | 16GB | 1590 |
| 4070 | 4608 | 8GB | 2175 |
| 4080 | 7424 | 12GB | 2175 |
| 4090 | 9728 | 16GB | 2040 |
Which GPU to pick?
It depends on what your focus is RIGHT NOW:
A) In the scenario where you’re getting started with deep learning/machine learning through guides, videos and tutorials. Usually tensorflow algorithms, then there’s no need to compile imagenet data or visual models on your GPU. This means a 4GB vRAM GPU like the 3050TI or any of the 4GB vRAM GPUs will be good.
B) If you want to work on your own project, you will likely run significantly larger models. If the your project is simple, then you should be okay with a laptop GPU. In this scenario, a 8GB-16GB vRAM GPU is best.
C) For large scale projects (research and companies work) that are aimed to develop a product. You have to use a computer clusters which have special GPUs for Data Science such as the NVIDIA H200 and H100 GPUs.
M1 & M2 & M3 & M4 vs NVIDIA GPUs: Deep Learning & Machine Learning
In the video above the “M” MacBooks are better for Machine & Deep Learning . The performance difference is ENORMOUS only because laptop GPUs do not have enough “memory” or ‘vRAM’ thus there’s a queue.
The MacBooks have “unified memory”. This means both the CPU & GPUs SHARE the same memory (there is no vRAM and no RAM only unified memory ) thus easily outperforming RTX laptops.
If the test is carried out with super small data sets as shown below:
You can get very misleading results! Even Intel CPUs can beat NVIDIA Cards when you have such a small data set.
32-96GB Unified Memory vs 16GB vRAM Benchmarks
A really great benchmark would be to test a model that’s large enough for both GPUs. Say use a Stack of NVIDIA GPUs vs a 96GB Unified memory MacBook. You bet the 4090 would outperform the M2 Models (just due to the large amount of processing units on NVIDIA GPUs). There’s no such benchmark yet however.
On laptops you are limited to 16GB vRAM. Thus the performance of M3 or M2 Chips would be higher if the data sets are much larger than 16GB vRAM.
3. Storage
Size: 256GB min
If you handle datasets in the gigabytes range and store them on your hard disk drive, you want at least 256GB or even 512GB.
If we are talking about reducing the time it takes to process datasets, storage size doesn’t matter.
Type : Which SSD generation?
If we are talking about transfering data from storage to RAM, the difference between types of SSDs is MINIMAL. Performance differences between generations (PCIe NVme 4.0 vs PCie NVme 5.0) are mostly useful for moving files in and out of your laptop.
In the scenario where your data set is much bigger than the RAM, the CPU will have to do the processing straight out of the storage drive, then yes choosing the fastest Solid State Drive (PCIe 5.0 as of 2024) will make a significant difference.
However, the performance of CPU-RAM data processing is WAY faster than CPU-SSD data processing so you WANT TO AVOID it.
Conclusion: the fastest solid state drive PCIe NVMe 5.0 isn’t something that’s a MUST for data science. As long as you. get ANY solid state drive you should rip all the usual benefits of SSDs (boot up your machine in 5 seconds, instantaneous code look up, launch software in seconds, etc).
A) Using the Cloud
If you’re going to use the Cloud because your datasets are extremely large (100GB range) then you want to pick an SSD with x2 the size of the largest data set you work with.
A 512GB SSD is a good start. As for uploading data to the cloud, it won’t be any faster with the fastest SSD. Ex: choosing a PCIe 5.0 won’t make uploading 100GB to the cloud any faster than a SATA III SSD.
PCIe 5.0 is already available on laptops as of late 2024.
5. Display
Size & Resolution: 15” FHD min (QHD if possible)
It’s not a requirement to have a large screen but it definitely helps for large data set visualization as you’ll get a bigger picture of your graphs and data rows. It also makes it easier to use the terminal (and SSH into cloud service/computing farms) while multitasking with several other windows next to it.
Also having a decently sized display with high resolution will make it MUCH easier on the eyes to read small code thus making it less likely to give you eye issues (and strain) in the future. Remember you will have to stare at the screen for several hours a day if not the entire day (at least when you’re getting started).
If budget allows and you’ll be mostly be using the cloud then I suggest you invest on QHD displays they have many advantages besides the extra crispy colors as shown in this post.
6. Cloud Services (For Newbies)
Cloud computing is basically paying for computer clusters to do the data crunching. These cloud services generally have thousands of computers, each with way more RAM than desktop support and they also use several processors that are MUCH MUCH faster than the fastest CPU found on laptops.
These computers go by the name of servers which implies they are specifically made to run a specific set of tasks. Ex: Running a file system, running a database, doing data analysis, running a web application, etc.
Since they have nearly unlimited hardware resources, this is the way to go for datasets of 100 GB and up.
In fact, it’s a good choice for any size. It will always turn out to be cheaper than buying a new computer since cloud services like Linode, AWS, Microsoft, and Digital Ocean are incredibly cheap.
As for myself, I have a subscription on two of these : Digital Ocean and AWS. The money I’ve spent is close to nothing compared to what I would’ve spend with a 128GB RAM desktop.
AWS (Amazon Web Services)
AWS is currently the biggest company in the Market of cloud computing services.
Sooner or later you will have to use AWS or a similar cloud service.
If you planned on doing more intense stuff (Neural Networks, Support Vector Machines on alot of data) even the most powerful desktop GPU will not cut it and you will be better off renting out an AWS instance.
Note that AWS has a free tier for you to get stated with so you’ve got nothing to lose at this point.
It’s not just about the need for unlimited computing power but also the fact that this is a SKILL you must learn if you ever want to land that 250k a year salary.
Using VNC (Virtual Network Computing)
You basically build the ideal (i.e. powerful) data analytics computer desktop.
Then you buy any cheap laptop of your choice, keep that powerful desktop running and use remote access software like TeamViewer, ANyDesk, TightVNC .
The problem here is that things are still going to be slow if your data sets (image) lie in the 100GB or more unless you buy a stack of NVIDIA GPUs (maximum is 24GB so you would have to buy x4 NVIDIA 4090Ti). If datasets are much smaller (>30GB), then it is a good option.
Amazon AWS EC2
I actually did the above but the problem was I started working with image data into the 50GB+ range and things started to slow down MASSIVELY. I got fed up resorted to use Amazon AWS EC2 for deep learning/machine learning ever since.
This service is very similar though. You make your own virtual computer with any OS of your choice and software of your choice. You could go as far as making it your only device of work.
For example, I installed a web based IDE for R on it (Rstudio),then went to the site that hosted the EC2 server and used R as if it was my very own personal computer.
Thus whenever I wanted to work, I could do it through any computer with an internet connection by simply visiting the site leaving all the processing to the server.
Cost: Depends on your choice for processor, RAM, GPU. Currently, there’s a 1yr trial which let’s you use a server at no cost (though with the lowest specs out of them all).
Advantages
Work with the server through any device with an internet connection and a keyboard.
Files are easy to access. No need to download anything just use and view them through the server.
Much less expensive than a powerful laptop
Server can be programmatically designed to scale depending on analysis needs using an API
Disadvantages:
If your laptop screen is small, you will struggle. It’s best to use a 15” or 17” screen if working from a laptop.
If your internet connection is slow, then your workflow will be slow too.
Can take some time to adjust.
7. OS: Mac vs Windows vs Linux
For some it may seem like only Mac and Linux are the way to go. But it’s all down to preference anyway. Most of the packages you will need work across all plataforms (Octave and R are good examples and have been availvable in all OSs for ages).
MAC/LINUX
Using Python on UNIX devices (both OSX & Linux are UNIX) is much easier due to better access to packages and package management.
Since Python is one of the most widely used languages for Data Science, you may think these two OSs are your best option.
That’s true also because you’ll have quick and early access to the latest libraries. That doesn’t mean you should not buy a windows laptop because you can install Linux on any windows laptop.
If you use do use Windows on a Windows laptop then you will have to wait for libraries to be compiled as binaries though.
Windows (OS)
If your solely working with Windows even with the new terminal on Windows, you will still need to do a lot of tweaks to set up all your algorithm and scripts for data science especially for sporadic and third party libraries whose documentation will be solely written for UNIX systems. The most widely used libraries and scripts for MatLab, S-Plus and SPSS, Python, Pandas, all the machine learning/deep learning algorithms, databases: PostgreSQL/MySQL will have a windows version and nice documentation for Windows though.
Note that Im NOT referring to windows LAPTOPS, I’m referring to the OS.
Cheaper Hardware, dGPUs and more
Windows laptops will give you the cheapest hardware and more powerful GPUs and more RAM than MacBooks (128GB on workstation windows laptops vs 64GB on the latest MacBook).
Unlike Macs, you can upgrade RAM on any windows laptop (Up to a limit predetermined by the motherboard).
Comments?
If you have any questions, questions or any suggestions. Please leave a comment below. Your input is taken seriously in our posts and will also be used for future updates.
Author Profile
- I am physicist and electrical engineer. My knowledge in computer software and hardware stems for my years spent doing research in optics and photonics devices and running simulations through various programming languages. My goal was to work for the quantum computing research team at IBM but Im now working with Astrophysical Simulations through Python. Most of the science related posts are written by me, the rest have different authors but I edited the final versions to fit the site's format.